我們終於來到了實際整合自己的聊天機器人的這一步了!在這裡,雖然我們會提供我們在colab上的程式碼供大家參考,但這篇文章主要不會深入探討程式碼。相反地,我們想分享我們在整合過程中的思考邏輯、所遇到的挑戰和問題,以及如何解決這些問題的經歷。
我們認為分享這些實際的經驗和過程,對讀者來說會有更深的啟示和參考價值。
首先,讓我們回顧一下這次專案中,我們打算實現的聊天機器人的功能。如下圖所示: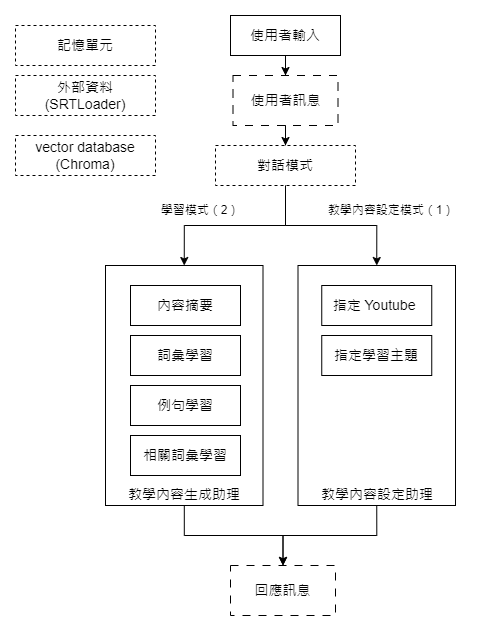
我們的學習助理目標是從影片中引導學習,涵蓋內容摘要、詞彙、例句,甚至相關詞彙的教學指導。整個過程大致分為兩個主要階段:
對於整個流程,我們相對應的流程圖如下。
首先,我們來講解「讀取教學內容階段」的具體目標。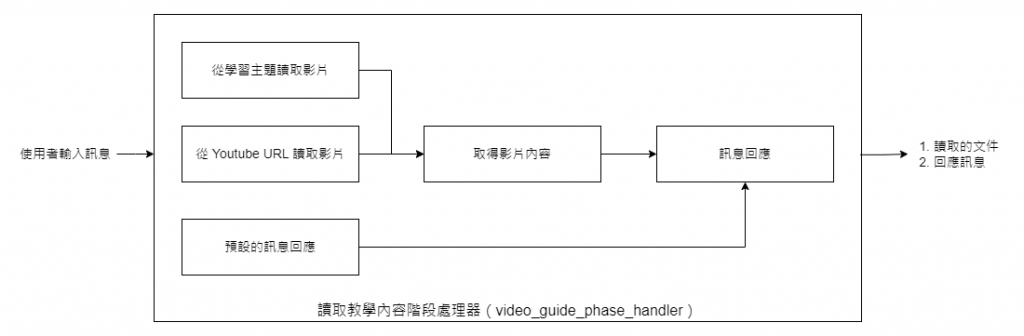
當我們收到使用者的訊息後,這個階段有兩個核心流程:
無論使用者選擇哪一流程,它們都會經由預先設計好的**SequentialChain**,該功能已連結好所有必要的子程序。最終,這個流程會有兩大主要輸出:影片的內容和針對使用者訊息的回覆。
為了優化使用者體驗,不論在哪一階段,我們都設計了一個專門的引導器。當使用者的輸入不符合我們的期待時,這個引導器會提供預設的訊息回應,確保使用者始終得到適當的指引。
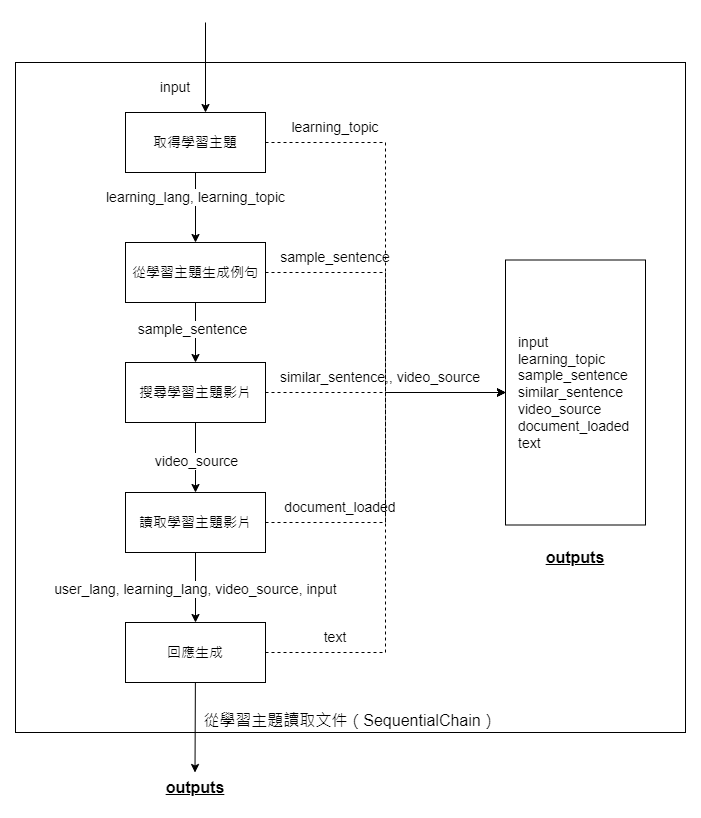
如前所述,我們的文件讀取階段主要分為兩個核心作業流程。在這一流程中,我們將所有重要的步驟用**SequentialChain連結起來。當使用者的訊息指示他們希望按照某個特定流程讀取影片(學習內容),我們的程序會如上圖所示操作。圖的左邊顯示了主要的執行流程:首先根據學習主題,接著生成一個例句,然後利用這個例句和向量資料庫進行搜尋,最後載入相應的影片。結束這些後,我們會使用LLMChain**進行回應,綜合前面的資訊。
此外,上方的流程圖清楚地顯示了各步驟所需的輸入參數以及執行後的輸出參數。例如,「讀取學習主題影片」的這個執行鏈在運作時需要**video_source這個參數,完成後則輸出document_loaded**的資訊。流程圖的最右側則列出了所有步驟執行後的總輸出值,而使用者也可以透過特定參數決定最後想要一起輸出的數值。
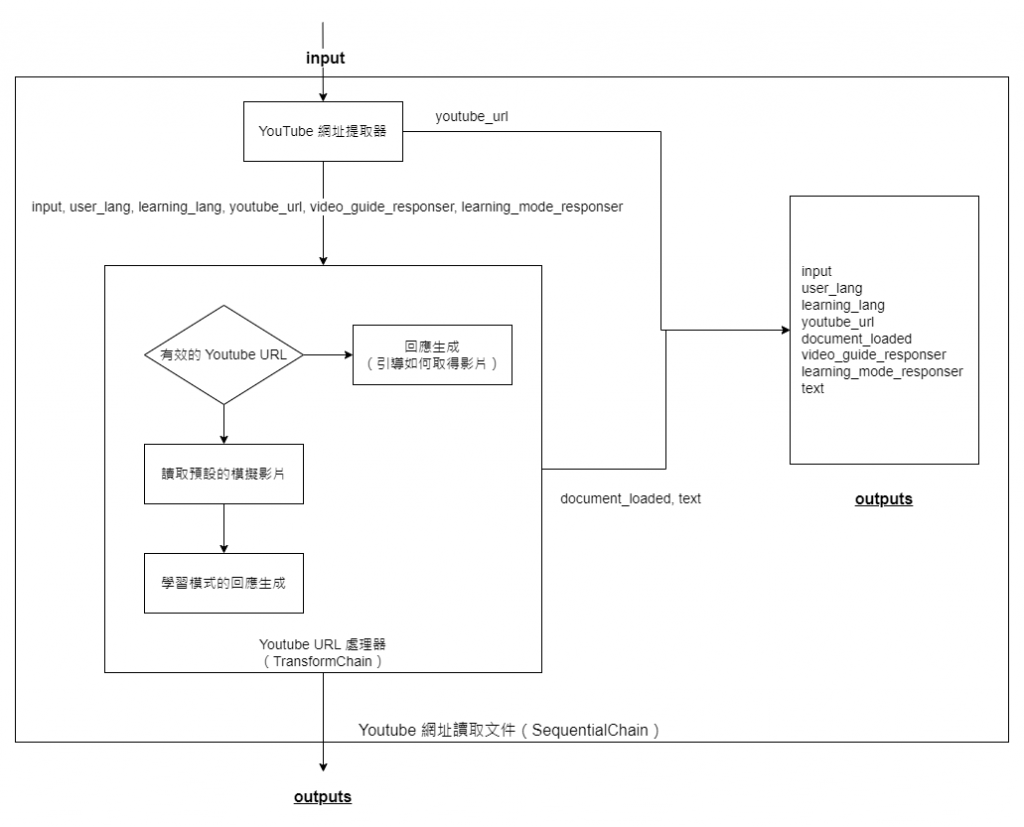
在我們的作業流程中,當系統偵測到使用者輸入了明確的 Youtube URL,會直接從該 URL 中讀取字幕內容。但由於此作業為模擬性質,我們實際上是從預先設定的影片字幕檔中進行讀取。
不過,在此過程中有一個小插曲。當我們嘗試設計提取 Youtube URL 的方法時,受限於時間,無法完美設計一個專門的提取器執行鏈。於是,我們選擇結合語言模型提示與傳統的程式邏輯判斷,作為我們的錯誤預防機制。具體來說,當系統發現提取的 Youtube URL 是無效的時,將導引至此階段的回應系統。反之,若 URL 正確,則繼續讀取內容,並進行下一階段的回應。
對於詳細的邏輯實作,有興趣的朋友可以參考以下的程式碼:
def process_youtube_url_extract_result(inputs: dict) -> dict:
"""
我們這裏有幾個任務。
1. 確保真的取得正式的 youtube url -> 讀取預設的 youtube 字幕檔 & 送到下個模式的引導器來做回覆
2. 無效的 youtube url -> 使用這個階段的引導器做回覆
"""
youtube_url = inputs["youtube_url"]
video_guide_responser = inputs["video_guide_responser"]
learning_mode_responser = inputs["learning_mode_responser"]
if is_valid_youtube_url(youtube_url):
loaded_document = load_document_from_srt_file(default_youtube_video_file)
print(f'calling {learning_mode_responser}')
inputs['video_source'] = youtube_url
leanring_mode_guide_response = learning_mode_responser(inputs)
return {
"document_loaded": loaded_document,
"text": leanring_mode_guide_response['text']
}
else:
video_guide_response = video_guide_responser(inputs)
return {
"document_loaded": None,
"text": video_guide_response['text']
}
youtube_url_process_chain = TransformChain(
input_variables=["youtube_url", "video_guide_responser", "learning_mode_responser"],
output_variables=["document_loaded", "text"],
transform=process_youtube_url_extract_result
)
在前面的描述中,我們已經逐步走過「取得學習影片」這一階段中各項子任務的執行流程。
對於這整個階段的子任務流程路由,我們本有意選擇 LangChain 提供的 MultiPromptChain 或 MultiRouterChain 來打造。但因為在應用 MultiRouterChain 的過程中,我們碰到了一些短期內難以迎刃而解的技術挑戰,所以轉而選擇獨立設計一套專屬的路由策略。具體的實作,您可以在 video_guide_phase_handler 函式中找到,詳細程式碼如下:
def video_guide_phase_handler(user_input: str) -> str:
global learning_document
# 路由執行鏈
router_result = video_guide_router_chain(user_input)
if verbose:
print(f'router_result: {router_result}')
ai_response = None
if router_result['destination'] == 'Topic extractor':
if verbose:
print(f'從指定的主題載入學習文件')
# load document from usage scenario
ai_response = topic_document_loading_overall_chain({
"learning_lang": learning_lang,
"user_lang": user_lang,
"input": user_input
})
learning_document = ai_response['document_loaded']
if verbose:
print('learning_document:', learning_document)
elif router_result['destination'] == 'YoutubeURL extractor':
if verbose:
print(f'從預設的srt文件載入學習文件')
ai_response = youtube_url_document_loading_overall_chain({
'input': user_input,
'user_lang': user_lang,
'learning_lang': learning_lang,
'video_guide_responser': video_guide_chain,
'learning_mode_responser': learning_mode_guide_chain,
})
learning_document = ai_response['document_loaded']
if verbose:
print('learning_document:', learning_document)
else:
# 預設的流程
ai_response = video_guide_chain({
'user_lang': user_lang,
'learning_lang': learning_lang,
'input': user_input,
})
return ai_response["text"]
這就是我們在構建 ChatBot 第一個核心階段時的整體架構和具體作法。如果您想深入了解我們的完整程式碼,歡迎點選這裡瀏覽: D28. LangChain 專案實做 - ChatBot 的整合(上).ipynb。


 iThome鐵人賽
iThome鐵人賽